
 Bertrand Florat
Tech articles
Others articles
Projects
Cours
Contact
Bertrand Florat
Tech articles
Others articles
Projects
Cours
Contact
Proper strings normalization for comparison purpose
 Bertrand Florat - Dec 22, 2020
Bertrand Florat - Dec 22, 2020
(This article has also been published at DZone)

TL;DR
In Java, do:
String normalizedString = Normalizer.normalize(originalString,Normalizer.Form.NFKD)
.replaceAll("[^\\p{ASCII}]", "").toLowerCase().replaceAll("\\s{2,}", " ").trim();
Nowadays, most strings are Unicode-encoded and we are able to work with many different native characters with diacritical signs/accents (like ö, é, À) or ligatures (like æ or ʥ). Characters can be stored in UTF-8 (for instance) and associated glyphs can be displayed properly if the font supports them. This is good news for cultural specificities respect.
However, we often observe recurring difficulties when comparing strings issued from different information systems and/or initially typed by humans.
Human brain is a machine to fill gaps. Hence it has absolutely no problem to read or type 'e' instead of 'ê'.
But what if the word 'tête' ('head' in French) is correctly stored in an UTF-8 encoded database but you have to compare it with an end-user typed text missing accents?
We also have often to deal with legacy systems or modern ones filled up with legacy data that doesn't support the Unicode standard.
Another simple illustration of this problem is the use of ligatures. Imagine a product database storing various items with an ID and a description. Some items contain ligatures (a combination of several letters joined together to create a single character like ’Œuf’ - egg in French). Like most French people, I have no idea of how to produce such a character, even using a French keyboard. I would spontaneously search the items descriptions using oeuf. Obviously, our code has to take care of ligatures if we want to return a useful result containing ’Œuf’.
How to fix that mess?
Rule #1: Don't even compare human text if you can
When you can, never compare strings from heterogeneous systems. It is surprisingly tricky to do it properly (even if it is possible to handle most cases like we will see below). Instead, compare sequences, UUID or any other ASCII-based strings without spaces or ‘special’ characters. Strings coming from different information systems have a good probability to store data differently (lower/upper case, with/without diacritics, etc.). On the contrary, good ids are free from encoding issues being plain ASCII strings.
Example:
System 1 : {"id":"8b286f72-b366-47a4-9537-59d39411979a","desc":"Œeuf brouillé"}
System 2 : {"id":"8b286f72-b366-47a4-9537-59d39411979a","desc":"OEUF BROUILLE"}
If you compare ids, everything is simple and you can go home early. If you compare description, you'll have to normalize it as a prerequisite or you'll be in big trouble.
Characters normalization is the action of computing a canonical form of a string. The basic idea to avoid false positives when comparing strings coming from several information systems is to normalize both strings and to compare the result of their normalization.
In the previous example, we would compare normalize("Œeuf brouillé") with normalize("OEUF BROUILLE"). Using a proper normalization function, we should then compare 'oeuf brouille' with 'oeuf brouille' but if the normalization function is buggy or partial, strings would mismatch. For example, if the normalize() function doesn't handle ligatures properly, you would get a false positive by comparing 'œuf brouille' with 'oeuf brouille'.
Rule #2: Normalize in memory
It is better to compare strings at the last possible moment and to do so in memory and not to normalize strings at storage time. This at least for two reasons:
-
If you only store a normalized version of your string, you lose information. You may need proper diacritics later for displaying purpose or others reasons. As an IT professional, one of your tasks is to never lose information humans provided you.
-
What if some items have been stored before the normalization routine has been set up? What if the normalization function changed over time?
To avoid these common pitfalls, simply compare in memory normalize(<data system 1>) with normalize(<data system 2>). The CPU overhead should be negligible if you don't compare thousands of items per second...
Rule #3: Always trim externally and internally
Another common trap when dealing with strings typed by humans is the presence of spaces at the beginning or in the middle of a sequence of characters.
As an example, look at these strings: ' Wiliam' (note the space at the beginning), 'Henry ' (note the space at the end), 'Gates III' (see the double space in the middle of this family name, did you notice it at first?).
Appropriate solution:
- Trim the text to remove spaces at the beginning and at the end of the text.
- Remove surnumerous spaces in the middle of the string.
In Java, one of the way to achieve it is:
s = s.replaceAll("\\s{2,}", " ").trim();
Rule #4: Harmonize letters casing
This is the most known and straightforward normalization method: simply put every letters to lower or upper case. AFAIK, there is no preference for one or the other choice. Most of developers (me included) use lower case.
In Java, just use toLowerCase():
s = s.toLowerCase();
Rule #5: Transform characters with diacritical signs to ASCII
When typed, diacritical signs are often omitted in favor of their ASCII version. For example, one can type the German word 'schon' instead of 'schön'.
Unicode proposes four Normalization forms that may be used for that purpose (NFC, NFD, NFKD and NFKC). Check-out this enlightening illustration.
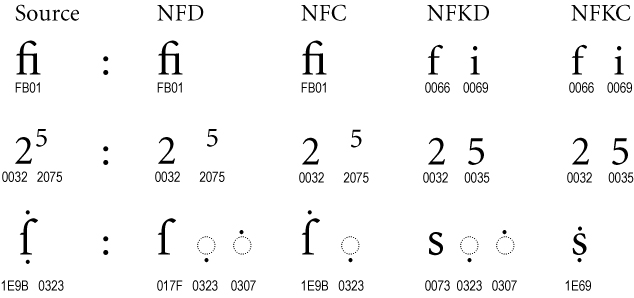{kind=link}
Detailing all these forms would go beyond the scope of this article but basically, keep in mind that some Unicode characters can be encoded either as a single combined character or as a decomposed form. For instance, 'é' can be encoded as \u00e9 code point or as the decomposed form '\u0065' ('e' letter) + '\u0301' (the diacritic '◌́'') afterward.
We will perform a NFD ("Canonical Decomposition") normalization method on the initial text to make sure that every character with accent is converted to its decomposed form. Then, all we have to do is to drop the diacritics and only keep the 'base' simple characters.
In Java, both operations can be done this way:
s = Normalizer.normalize(s, Normalizer.Form.NFD)
.replaceAll("[^\\p{ASCII}]", "");
Note: even if this code covers this current issue, prefer the NFKD transformation to deal with ligatures as well (see below).
Rule #6: Decompose ligatures to a set of ASCII characters
The other thing to understand is that Unicode maintain some compatibility mapping between about 5000 ‘composite’ characters (like ligatures or roman precomposed roman numeral) and a list of regular characters. Characters supporting this feature are documented (check the 'decomposition' attribute in Unicode characters documentation).
For instance; the roman numeral Ⅻ (U+216B) can be decomposed with NFKD normalization as a 'X' and two 'I'. Likewise, the ij (U+0133) character (like in 'fijn' - 'nice' in Dutch) can be decomposed into a 'i' and a 'j'.
For these kinds of 'Siamese twins' characters, we have to apply the NFKD ("Compatibility Decomposition") normalization form that both decompose the characters (see 'Rule #5' previously) but also maps ligatures to several 'base' characters. You can then drop the remaining diacritics.
In Java, use:
s = Normalizer.normalize(s, Normalizer.Form.NFKD)
.replaceAll("[^\\p{ASCII}]", "");
Now the bad news : for obscure reasons, Unicode doesn't support decomposition equivalence of some widely used ligatures like French 'œ' and 'æ' or the German eszett 'ß'. If you need to handle them, you will have to write your own replacements before applying the NFKD normalization :
s = s.replaceAll("œ", "oe");
s = s.replaceAll("æ", "ae");
s = Normalizer.normalize(s, Normalizer.Form.NFKD)
.replaceAll("[^\\p{ASCII}]", "");
Rule #7: Beware punctuation
This a more minor issue but according to your context you may want to normalize some special punctuation characters as well.
For example, in a literary context like a text-revision software, it may be a good idea to map the em/long dash ('—') character to the regular ASCII hyphen ('-').
AFAIK, Unicode doesn't provide mapping for that, just do it yourself the old good way:
s = s.replaceAll("—", "-");
Final word
String normalization is very helpful to compare strings issued from different systems or to perform appropriate comparisons. Even fully English localized projects can benefit from it, for instance to take care of case or trailing spaces or when dealing with foreign words with accents.
This article exposes some of the most important points to take into consideration but it is far from exhaustive. For instance, we omitted Asian characters manipulation or cultural normalization of semantically equivalents items (like 'St' abbreviation of 'Saint') but I hope it is a good start for most projects.
References
http://www.unicode.org/reports/tr15/
https://docs.oracle.com/javase/tutorial/i18n/text/normalizerapi.html
https://en.wikipedia.org/wiki/Unicode_equivalence#Normalization
https://minaret.info/test/normalize.msp